Health Check Function
Following auto-scaling, this function detects abnormality on the scaled-out virtual servers and starts recovery automatically.
Functions Included
You can use the following functions for scaled-out virtual servers:
- Health check function, for scaled-out virtual servers
-
Auto recovery function, for virtual servers where abnormality was detected by the health check function
Figure: Operation of the Auto Recovery Function on a Virtual Server Where Abnormality Was Detected by the Health Check Function
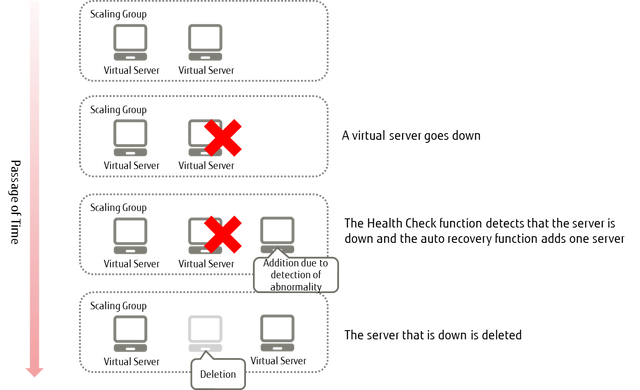
Auto Recovery Function for a Virtual Server Where Abnormality Was Detected by the Health Check Function
To use this function, add the following items to the appropriate categories of the settings for auto-scaling:
-
Settings for the health check function for scaling groups
Table 1. List of Scaling Group Settings Regarding the Health Check Function Item Description Required Cool down period (Cooldown) Specify this setting, in seconds, to prevent the next scaling operation from starting immediately after the previous scaling operation was completed (Formula for Estimating Cool Down Period after Auto-Scaling)
Important: When you use this function in conjunction with auto-scaling based on the monitoring of thresholds, such as CPU usage rate, specify this field instead of specifying the cool down period in the scaling policies.Maximum number (MaxSize) Specify the maximum number of virtual servers to be scaled
Tip: When you use this function, we recommend that you specify a value which is the minimum number plus 1 or more.Note: When the maximum number of virtual servers have been created and abnormality is detected on a virtual server, the addition of virtual servers is not carried out, and only the deletion of virtual servers is carried out.Yes Minimum number (MinSize) Specify the minimum number of virtual servers to be scaled
Tip: This is the number of servers that are created initially when the stack is registered.Yes Health check type (HealthCheckType) Supports only "ELB." When you specify the load balancer name and this parameter, the auto recovery function for virtual servers where abnormality was detected by the health check function is enabled. Time to wait before starting health check (HealthCheckGracePeriod) Specify this setting, in seconds, to wait for a period after scaled-out virtual servers are started before starting the health check -
Settings for scaling policies
Table 2. List of Scaling Policy Settings Regarding the Health Check Function Item Description Required Scaling type (AdjustmentType) Specify "ChangeInCapacity" Yes Cool down period (Cooldown) Specify this setting, in seconds, to prevent the next scaling operation from starting immediately after the previous scaling operation was completed (Formula for Estimating Cool Down Period after Auto-Scaling) Scaling value (ScalingAdjustment) Specify the scaling adjustment value
Note: Specify a value which is lower than the maximum number that is set for the scaling group, and within the range of 1 to 5.Yes -
Settings for alarms
Table 3. List of Alarm Settings Regarding the Health Check Function Item Description Required Action (alarm_actions) Specify the URL of the action required in order to delete the virtual server that is experiencing abnormality Comparison operator (comparison_operator) Specify comparison operators that are used with threshold values
- "le": Less than or equal
- "ge": Greater than or equal
- "eq": Equal to
- "lt": Less than
- "gt": Greater than
- "ne": Not equal
Number of times that constitutes alarm status (evaluation_periods) Specify the number of times the threshold condition must be reached in order to be considered to be in alarm status Meta data search condition (matching_metadata) Specify "{'resource_id': <load balancer name>}" Meter name (meter_name) Specify "fcx.loadbalancing.instance.unhealthy" Yes Period that constitutes alarm status (period) Specify how long of a period (sec) the threshold must be exceeded in order to be considered to be in alarm status Statistic type (statistic) Specify "min" to count the virtual servers that are experiencing abnormality Threshold (threshold) Specify the threshold for the number of virtual servers that are experiencing abnormality. Specify the same value as the scaling adjustment value (ScalingAdjustment) that you specified in the scaling policy settings. If you specify two or more, auto recovery will not be performed until the number of servers experiencing abnormality reaches or exceeds the specified value. Yes Repeat actions (repeat_actions) Specify "true" to use the health check function
The number of virtual servers that will be added after execution of the auto recovery function is determined based on the scaling policy that is set for the scaling group that is using the health check function. When auto recovery is performed, the number of virtual servers is determined according to the following formula:
(Number of virtual servers running in the scaling group before auto recovery is performed) + (number of virtual servers that will be added according to the setting in the scaling policy) - (number of virtual servers which were determined to be experiencing abnormality by the health check)