ヘルスチェック機能
対象リージョン:東日本第1/第2、西日本第2
オートスケール実行後、スケールアウトした仮想サーバに対して異常状態を検知し、自動で復旧を開始する機能です。
提供機能
スケールアウトした仮想サーバに対して、以下の機能を提供します。
- スケールアウトした仮想サーバに対する、ヘルスチェック機能
-
ヘルスチェック機能で異常を検知した仮想サーバへの、自動復旧機能
図: ヘルスチェック機能で検知した異常仮想サーバへの、自動復旧機能の動作イメージ 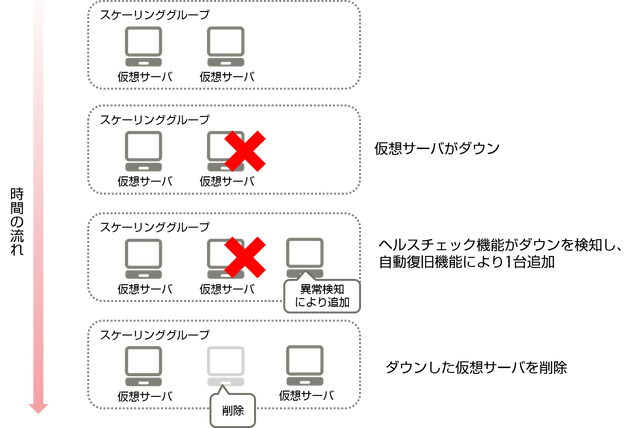
ヘルスチェック機能で異常を検知した仮想サーバへの自動復旧機能
本機能を利用するには、オートスケールの各設定に、以下の項目を追加で設定します。
-
スケーリンググループのヘルスチェック機能設定
表 1. ヘルスチェック機能に関するスケーリンググループ設定内容一覧 項目 説明 必須 クールダウン時間 (Cooldown) 前回のスケーリング処理実行後、次のスケーリング処理がすぐ開始されないように、抑止する時間を秒単位で指定する(見積式のオートスケールのクールダウン時間 見積式を参照)
注: 本機能とCPU使用率などのしきい値監視によるオートスケールを同時に使用する場合、スケーリングポリシーの「クールダウン時間」を指定せず、本項目を指定してください。最大数 (MaxSize) スケーリングする仮想サーバの最大数を指定する
本機能を使用する場合、最小数+1以上の値を指定することを推奨します。
注: 最大数まで仮想サーバを作成している状況で、仮想サーバの異常を検知した場合、仮想サーバは追加されず、削除だけが実施されます。◯ 最小数 (MinSize) スケーリングする仮想サーバの最小数を指定する
スタック登録時の初期作成台数となります。
◯ ヘルスチェックタイプ (HealthCheckType) "ELB"だけサポートする。ロードバランサー名を指定し、本パラメーターを指定した場合、ヘルスチェック機能を用いた異常仮想サーバの異常を検知した自動復旧機能が有効になる ヘルスチェック開始までの時間 (HealthCheckGracePeriod) スケールアウトした仮想サーバが起動したあと、実際にヘルスチェックを開始するまでの時間を秒単位で指定する -
スケーリングポリシーの設定
表 2. ヘルスチェック機能に関するスケーリングポリシー設定内容一覧 項目 説明 必須 増減タイプ (AdjustmentType) "ChangeInCapacity"を指定する ◯ クールダウン時間 (Cooldown) 前回のスケーリング処理実行後、次のスケーリング処理がすぐ開始されないように、抑止する時間を秒単位で指定する(見積式のオートスケールのクールダウン時間 見積式を参照) 増減値 (ScalingAdjustment) スケール変更値を指定する
スケーリンググループ設定の「最大数」よりも小さい値、かつ1~5の範囲で指定してください。
◯ -
アラームの設定
表 3. ヘルスチェック機能に関するアラーム設定内容一覧 項目 説明 必須 アクション (alarm_actions) 異常となった仮想サーバを削除するために、必要なアクションの URLを指定する 比較演算子 (comparison_operator) しきい値との比較演算子を指定する
- "le":以下
- "ge":以上
- "eq":等しい
- "lt":より小さい
- "gt":より大きい
- "ne":等しくない
アラーム判定回数 (evaluation_periods) 何回しきい値条件を満たしたときにアラーム状態と判断するか、その回数を指定する メタデータ検索条件 (matching_metadata) "{'resource_id': ロードバランサー名}" を指定する メーター名 (meter_name) "fcx.loadbalancing.instance.unhealthy" を指定する ◯ アラーム判定期間 (period) どれくらいの時間しきい値条件を満たしたらアラーム状態と判断するか、その時間(秒)を指定する 統計種別 (statistic) 異常となった仮想サーバ数を数えるよう、"min"を指定する しきい値 (threshold) しきい値となる異常仮想サーバの数を指定する。スケーリングポリシー設定で指定するスケール変更値(ScalingAdjustment)と同一の値を指定する。また、2以上の値を指定した場合、指定した値以上の仮想サーバが異常になるまで、自動復旧は行われない ◯ アクション繰り返し (repeat_actions) ヘルスチェック機能を使用する場合は"true"を指定する
注:
-
自動復旧機能が動作した場合に追加される仮想サーバ数は、ヘルスチェック機能を使用するスケーリンググループに設定されるスケーリングポリシーに従います。自動復旧が行われると仮想サーバの数は以下の式のようになります。
「自動復旧前のスケーリンググループ内で起動している仮想サーバの数」+「スケーリングポリシーに設定されている追加する仮想サーバの数」-「ヘルスチェックで異常とされた仮想サーバの数」
-
異常を検知した仮想サーバを削除した結果、スケーリンググループで設定した仮想サーバの最小数を下回ることがあります。その場合、設定されている最小数まで自動的に仮想サーバが追加されます。