オートスケール設定
対象リージョン:全リージョン
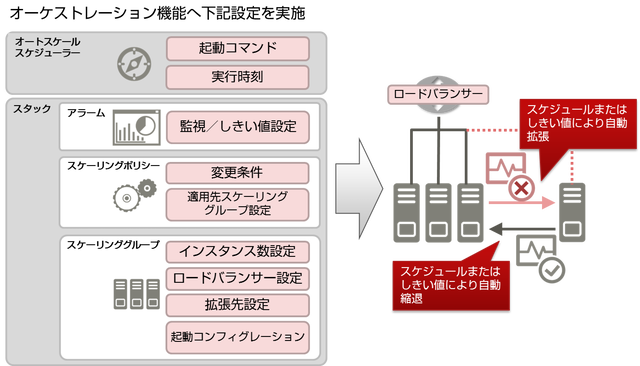
スタックに定義されている仮想サーバの台数などについて、特定の条件をスケーリンググループとして設定し、条件に従ってリソースの増減を自動的に制御する機能を提供します。
- 複数のアベイラビリティゾーン間でオートスケールをすることはできません。
- テンプレートで作成したスタックを更新すると、すでに配備されているリソースは削除され、再構築されます。
- オートスケールでは、仮想サーバのフレーバーを変更できません。
- 東日本リージョン3/西日本リージョン3のオートスケールでは、ロードバランサーを設定できません。
オートスケールの動作に関して、以下の設定機能を提供します。
スケーリンググループ管理機能
以下の項目を設定してスケーリンググループを作成し、スタック内に登録します。スケールアウトした仮想サーバに対して異常状態を検知し、自動で復旧を開始するヘルスチェック機能に関する設定もできます。
| 項目 | 説明 | 必須 | |
|---|---|---|---|
|
東日本第1/第2 西日本第2 |
東日本第3 西日本第3 |
||
| クールダウン時間 (Cooldown) | 前回のスケーリング処理実行後、次のスケーリング処理がすぐ開始されないように、抑止する時間を秒単位で指定する | ||
| 起動コンフィグレーション名 (LaunchConfiguration) | 仮想サーバ起動のための起動コンフィグレーション名を指定する | ◯ | ◯ |
| ロードバランサー名 (LoadBalancerNames) | スケーリング処理に含めるロードバランサー名をリスト形式で指定する | ※1 | |
| 最大数 (MaxSize) | スケーリングする仮想サーバの最大数を指定する | ◯ | ◯ |
| 最小数 (MinSize) |
スケーリングする仮想サーバの最小数を指定する ヒント: スタック登録時の初期作成台数となります。
|
◯ | ◯ |
| アベイラビリティゾーン名 (AvailabilityZones) | スケーリンググループの作成先アベイラビリティゾーン名を指定する | ◯ | ※2 |
| サブネットIDリスト (VPCZoneIdentifier) | アベイラビリティゾーン名で指定した、アベイラビリティゾーンに存在するサブネットIDをリスト形式で指定する | ※2 | |
※1: ロードバランサーは設定できません。
※2: 設定不要です。
スケーリングポリシー設定
以下の項目を指定して、スケーリングポリシーを設定します。
| 項目 | 説明 | 必須 | |
|---|---|---|---|
|
東日本第1/第2 西日本第2 |
東日本第3 西日本第3 |
||
| 増減タイプ (AdjustmentType) |
仮想サーバ台数の増減方法を、以下のタイプから選択して指定する
|
◯ | ◯ |
| スケーリンググループ名 (AutoScalingGroupName) | スケーリングポリシーを設定する対象のスケーリンググループ名を指定する | ◯ | ◯ |
| クールダウン時間 (Cooldown) | 前回のスケーリング処理実行後、次のスケーリング処理がすぐ開始されないように、抑止する時間を秒単位で指定する | ||
| 増減値 (ScalingAdjustment) |
増減タイプ指定の内容に対応したスケール変更値を指定する 例)増減タイプにChangeInCapacity、変更値に「-1」を指定した場合、ポリシーの実行時に仮想サーバが1つ削除される |
◯ | ◯ |
起動コンフィグレーション設定
スケーリングポリシーが実行され、追加される仮想サーバが実際に起動する際の設定処理を定義しておきます。
| 項目 | 説明 | 必須 | |
|---|---|---|---|
|
東日本第1/第2 西日本第2 |
東日本第3 西日本第3 |
||
| イメージID (ImageId) | 起動する仮想サーバで使用するイメージを、イメージIDまたはイメージ名称で指定する | ◯ | ◯ |
| 仮想サーバタイプ (InstanceType) | 起動する仮想サーバのタイプ名(フレーバー名)を指定する | ◯ | ◯ |
| キー名 (KeyName) | 起動する仮想サーバに設定するキーペアのキー名を指定する | ||
| セキュリティグループ (SecurityGroups) | 起動する仮想サーバに設定するセキュリティグループ名をリスト形式で指定する | ||
| ユーザーデータ (UserData) | 仮想サーバ起動時に実行するユーザーデータを指定する | ||
| ブロックデバイスマッピング設定のリスト (BlockDeviceMappingsV2) | 起動する仮想サーバにブロックストレージとしてアタッチするために、ブロックデバイスマッピング設定を記述する | ||
アラームとの連携
監視サービスにおけるアラーム設定では、しきい値に達した場合のアクションとしてスケーリングポリシーを指定します。アラームのしきい値の設定内容によってスケーリングポリシーを呼び分けることで、負荷に応じたオートスケーリングができます。
オートスケール設定例
オートスケールの条件を記載したスタック定義の記述例を示します。本例では以下の条件を設定しています。
-
スケーリンググループとして以下を定義
- オートスケールした仮想サーバを分散対象とするためのロードバランサー指定(HTTP、ポート80への通信を負荷分散)
- 仮想サーバの最大台数は3
- 仮想サーバの最小台数は2
- オートスケールした仮想サーバを接続するサブネット
- 起動コンフィグレーション(parameters句で宣言されている変数を利用して値を指定)
-
スケーリングポリシーとして以下の2つを定義
- web_server_scaleout_policy:増減タイプは"ChangeInCapacity"を指定、アラーム発生時に追加する仮想サーバ数は1台 (+1)
- web_server_scalein_policy:増減タイプは"ChangeInCapacity"を指定、アラーム発生時に削除する仮想サーバ数は1台 (-1)
-
アラームとして以下の2つを定義
- cpu_alarm_high:CPU使用率が50%を超えた時間が1分以上継続したことを検知→web_server_scaleout_policyを実行
- cpu_alarm_low:CPU使用率が15%以下の時間が1分以上継続したことを検知→web_server_scalein_policyを実行
スタック定義の記述例(東日本第1/第2、西日本第2リージョンの場合):
heat_template_version: 2013-05-23
description:
Autoscaling sample template.
parameters:
az:
type: string
default: jp-east-1a
param_image_id:
type: string
# ImageID of CentOS
default: 1234abcd-5678-ef90-9876-fedc5432dcba
param_flavor:
type: string
default: standard
key_name:
type: string
description: SSH key to connect to the servers
default: sample_keypair00
autoscale_security_group:
type: comma_delimited_list
default: sample_SG00
resources:
web_server_group:
type: FCX::AutoScaling::AutoScalingGroup
properties:
AvailabilityZones: [{get_param: az}]
LaunchConfigurationName: {get_resource: launch_config}
MinSize: '2'
MaxSize: '3'
# subnet ID for auto-scaling
VPCZoneIdentifier: [38e6630f-3257-4ee8-a006-f6d57ceaa2c3]
LoadBalancerNames:
- {get_resource: fj_elb}
launch_config:
type: FCX::AutoScaling::LaunchConfiguration
properties:
ImageId: { get_param: param_image_id }
InstanceType: { get_param: param_flavor }
KeyName: {get_param: key_name}
SecurityGroups: {get_param: autoscale_security_group}
BlockDeviceMappingsV2: [{source_type: 'image', destination_type: 'volume', boot_index: '0', device_name: '/dev/vda', volume_size: '40', uuid: {get_param: param_image_id}, delete_on_termination: true}]
fj_elb:
type: FCX::ExpandableLoadBalancer::LoadBalancer
properties:
# subnet ID for auto-scaling
Subnets: [38e6630f-3257-4ee8-a006-f6d57ceaa2c3]
Listeners:
- {LoadBalancerPort: '80', InstancePort: '80',
Protocol: 'HTTP', InstanceProtocol: 'HTTP' }
HealthCheck: {Target: 'HTTP:80/healthcheck', HealthyThreshold: '3',
UnhealthyThreshold: '5', Interval: '30', Timeout: '5'}
Version: 2014-09-30
Scheme: internal
LoadBalancerName: fjsampleELBaz1
web_server_scaleout_policy:
type: FCX::AutoScaling::ScalingPolicy
properties:
AdjustmentType: ChangeInCapacity
AutoScalingGroupName: {get_resource: web_server_group}
Cooldown: '60'
ScalingAdjustment: '1'
web_server_scalein_policy:
type: FCX::AutoScaling::ScalingPolicy
properties:
AdjustmentType: ChangeInCapacity
AutoScalingGroupName: {get_resource: web_server_group}
Cooldown: '60'
ScalingAdjustment: '-1'
cpu_alarm_high:
type: OS::Ceilometer::Alarm
properties:
description: Scale-out if the average CPU > 50% for 1 minute
meter_name: fcx.compute.cpu_util
statistic: avg
period: '60'
evaluation_periods: '1'
threshold: '50'
alarm_actions:
- {get_attr: [web_server_scaleout_policy, AlarmUrl]}
matching_metadata: {'metadata.user_metadata.groupname': {get_resource: 'web_server_group'}}
comparison_operator: gt
cpu_alarm_low:
type: OS::Ceilometer::Alarm
properties:
description: Scale-in if the average CPU < 15% for 1 minute
meter_name: fcx.compute.cpu_util
statistic: avg
period: '60'
evaluation_periods: '1'
threshold: '15'
alarm_actions:
- {get_attr: [web_server_scalein_policy, AlarmUrl]}
matching_metadata: {'metadata.user_metadata.groupname': {get_resource: 'web_server_group'}}
comparison_operator: ltスタック定義の記述例(東日本リージョン3/西日本リージョン3の場合):
heat_template_version: 2017-02-24
description: Example auto scale group, policy and alarm
resources:
scaleup_group:
type: OS::Heat::AutoScalingGroup
properties:
cooldown: 60
desired_capacity: 1
min_size: 1
max_size: 3
resource:
type: OS::Nova::Server
properties:
key_name: monitring-dev2
block_device_mapping_v2:
[{boot_index: '0', device_name: '/dev/vda', volume_size: 10, image: 'Ubuntu Server 16.04 LTS (English) 01', delete_on_termination: true}]
flavor: S3-1
name: "test_vm"
networks:
- network : test-net
scaleup_policy:
type: OS::Heat::ScalingPolicy
properties:
adjustment_type: change_in_capacity
auto_scaling_group_id: {get_resource: scaleup_group}
cooldown: 60
scaling_adjustment: 1
alarm_cpu:
type: OS::PMM::Alarm
properties:
name: 'alarm_vm_cpu'
target_type: 'stack'
object_id: { get_param: "OS::stack_id" }
metric_type: 'instance.cpu.usage'
interval_duration: '1m'
from: '1m'
aggregation_function: 'avg'
comparison_function: 'above'
threshold: 80
alert_count: 1
alarm_action: ['autoscale']
autoscale_url: { get_attr: [scaleup_policy, signal_url]
}東日本第1/第2、西日本第2リージョンでは、以下の両方の条件を満たす場合、仮想サーバのユーザー名が「k5user」ではなく「cloud-user」になります。
- 仮想サーバのOSがCentOSまたはRed Hat Enterprise Linuxの場合
- Heatテンプレートを利用して作成したスタックから、新規に仮想サーバを配備した場合